Apache Kafka® upgrade procedure
One of the benefits of using a managed service like Aiven for Apache Kafka® is the automated upgrade procedure.
The upgrade procedure is executed during:
- maintenance updates
- plan changes
- cloud region migrations
- manual node replacements performed by an Aiven operator
All the above operations involve creating new broker nodes to replace existing ones.
Upgrade procedure steps
To demonstrate what steps are taken during the automated upgrade procedure, we'll look at the example for a 3-node Apache Kafka service visualised below:
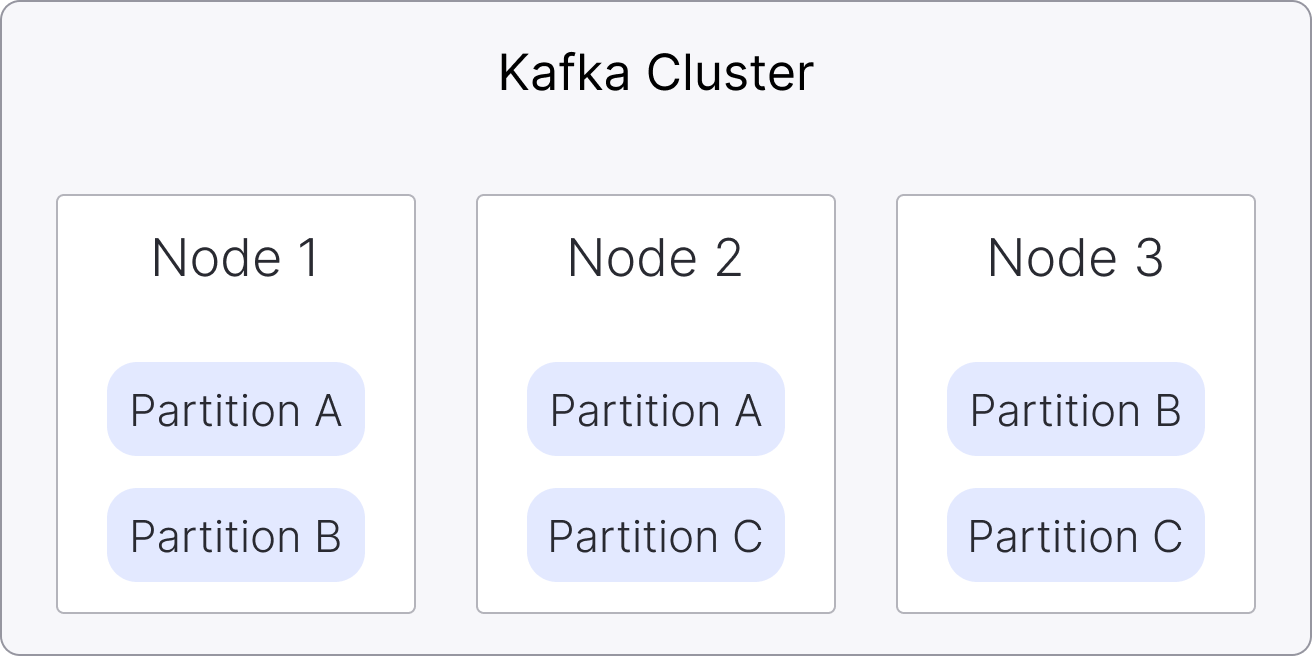
The following set of steps are executed during an upgrade procedure:
-
New Apache Kafka® nodes are started alongside the existing nodes
-
Once the new nodes are running, they join the Apache Kafka cluster
noteThe Apache Kafka cluster now contains a mix of old and new nodes
-
The partition data and leadership is transferred to new nodes
 warning
warningThis step is CPU intensive due to the additional data movement overhead.
-
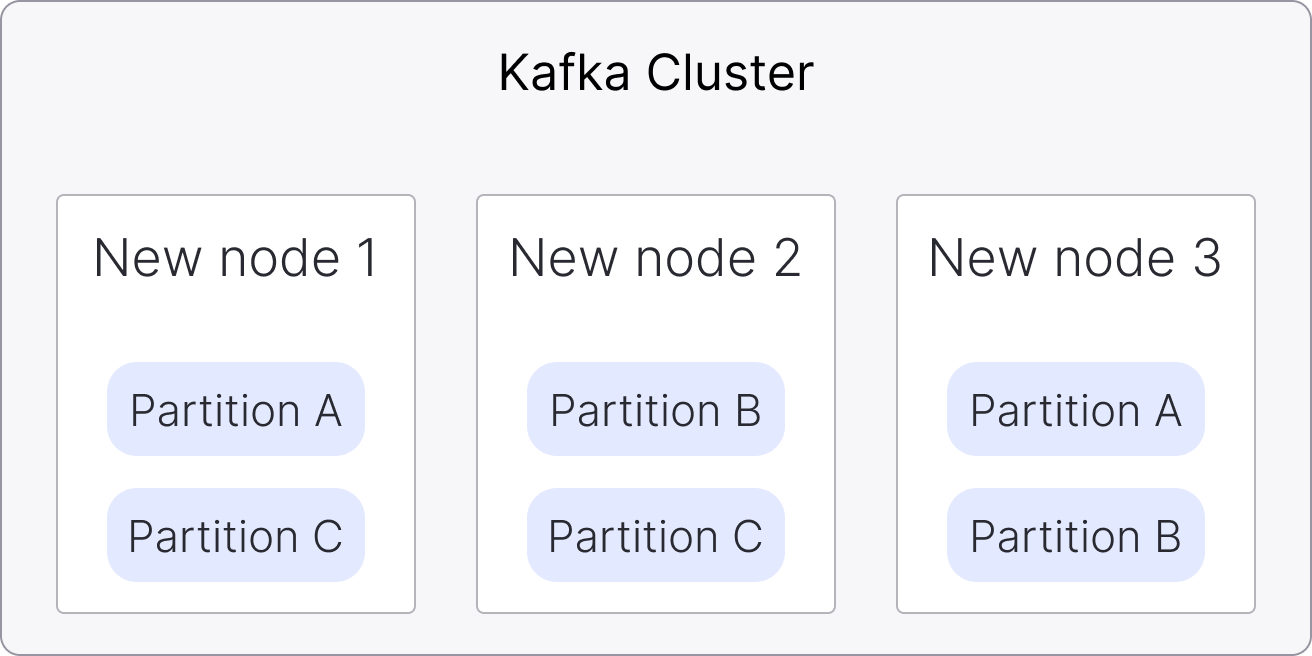
Once old nodes don't have any partition data, they are retired from the cluster.
noteDepending on the cluster size more new nodes are added (by default up to 6 nodes at a time are replaced)
-
The process is completed once the last old node has been removed from the cluster:
Zero upgrade downtime
The upgrade process described above has no downtime, since there always be active nodes in cluster and the same service URI will resolve to all the active nodes. But, since the upgrade generates extra load during the transfer of partitions, the overall cluster performance can slow down or even prevent the progress of normal work if the cluster is already under heavy load.
Apache Kafka client trying to produce or consume messages might face
warning leader not found messages as the partitions are moved between
brokers. This is normal and most client libraries handle this
automatically but the warnings may look alarming in the logs, to
understand more read the
dedicated document.
Upgrade duration
The upgrade duration can vary quite significantly and depends on:
- The amount of data stored in the cluster
- The number of partitions: each partition represents an overhead since also partition leadership needs to be moved to the new nodes
- The spare resources available on the cluster: if the cluster is already under heavy load, the resources dedicated to the upgrade procedure will be minimal
To achieve quicker upgrades, Aiven therefore recommends running the procedure during low periods of low load to reduce the overhead of producers and consumers. If a service is already tightly constrained on resources, it is recommend to disable all non-essential usage during the upgrade to allow more resources to be used on coordinating and moving data between nodes.
Upgrade rollback
Rollback is not available since old nodes are deleted once they are removed from the cluster.
Nodes are not removed from the cluster while they hold data. If an upgrade doesn't progress, the nodes are not removed since that would lead to data loss.
It is possible to downgrade from a larger service plan back to a smaller service plan, if there is enough disk capacity on the smaller plan, via the Aiven Console or the Aiven CLI.
When changing the node type during a service plan change, the upgrade procedure remains the same. In case of downgrading to a service plan with nodes having lesser CPUs, memory, or disk, the latest system software versions will be used for all newly created nodes. The upgrade mechanism, as explained in this document, will be employed to transfer data to the new nodes.
Upgrade impact and risks
During the upgrade procedure additional CPU load is generated by partition leadership coordination and streaming data to new nodes. To mitigate the risk run the upgrade at a time of low traffic and/or reduce the normal workload on the cluster by disabling non-essential producers and consumers.
Specifically when upgrading to a smaller plan, the disk could reach the maximum allowed limit which can prevent progress of the procedure. To mitigate the risk check the disk usage before the upgrade and evaluate the amount of space left.
In case of emergency, our operations team is able to help by adding additional volumes to the old nodes temporarily.