Handle PostgreSQL® node replacements when using Debezium for change data capture
When running a Debezium source connector for PostgreSQL® to capture changes from an Aiven for PostgreSQL® service, there are some activities on the database side that can impact the correct functionality of the connector.
As example, when the source PostgreSQL service undergoes any operation which replaces the nodes (such as maintenance, a plan or cloud region change or a node replacement), the Debezium connector loses connection to the PostgreSQL database. The connector is able to recover from temporary errors to the database and start listening for change events again after a restart of the related task. However, in some cases, the PostgreSQL replication slot used by Debezium can start lagging and therefore cause a growing amount of WAL logs.
Use the GitHub repository to set up and test a Debezium - PostgreSQL node replacement scenario. For guidance, follow the Aiven Debezium help article.
Common Debezium errors related to PostgreSQL node replacement
In cases when the Debezium connector can't recover during or after the PostgreSQL node replacements, the following errors are commonly shown in logs:
# ERROR 1
org.apache.kafka.connect.errors.ConnectException: Could not create PostgreSQL connection
# ERROR 2
io.debezium.DebeziumException: Could not execute heartbeat action (Error: 57P01)
# ERROR 3
org.PostgreSQL.util.PSQLException: ERROR: replication slot "SLOT_NAME" is active for PID xxxx
The above errors are unrecoverable, meaning that they require a restart of the connector tasks to resume operations again.
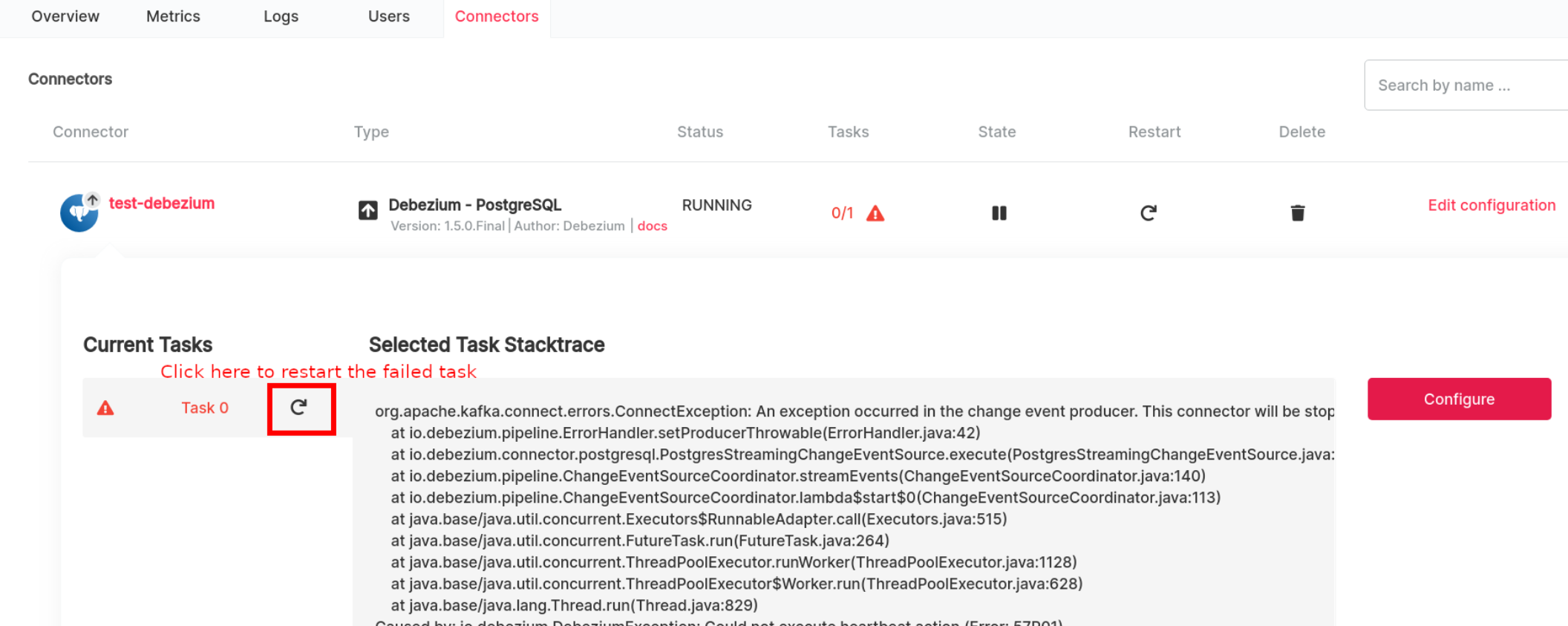
A restart can be performed manually either through the Aiven
Console, in under the Connectors tab
console or via the Apache Kafka® Connect REST
API.
You can get the service URI from the Aiven
Console, in the service detail page.
For automatically restarting tasks, you can set
"_aiven.restart.on.failure": true in the connector's configuration (
check the related
article).
Aiven automatically check tasks status for errors every 15 minutes but
the interval can be customised if needed.
Handle growing replication lag after Debezium connector restart
As per the dedicated Debezium docs, there are two main reasons why growing replication lag can happen after the Debezium connector is restarted:
-
Too many updates are happening in the tracked database, but only a few of these updates pertain to the tables and schemas that the connector is monitoring for changes.
Such issue can be resolved by enabling periodic heartbeat events and setting the (
heartbeat.interval.ms) connector configuration property. -
The PostgreSQL instance contains multiple databases and one of them is a high-traffic database.
Debezium captures changes in another database that is low-traffic in comparison to the other database. Debezium then cannot confirm the LSN (
confirmed_flush_lsn) as replication slots work per-database and Debezium is not invoked. As WAL is shared by all databases, the amount used tends to grow until an event is emitted by the database for which Debezium is capturing changes.
During the Aiven testing, the above situations have been observed to happen in 2 scenarios:
-
The tables which the Debezium connector is tracking has not had any changes, and heartbeats are not enabled in the connector.
-
The tables which the Debezium connector is tracking has not had any changes, heartbeats are enabled (via
heartbeat.interval.msandheartbeat.action.query), but the connector is not sending the heartbeat.noteThe Debezium heartbeat problem is discussed in the bug DBZ-3746 .
Clear the replication lag
To clear the replication lag, resume the database activities (if have paused all traffic to the database) or make any changes to the tracked tables to invoke the replication slot. Debezium would then confirm the latest LSN and allow the database to reclaim the WAL space.
Ensure Debezium gracefully survives a PostgreSQL node replacement
To prevent data loss (Debezium missing change events) during PostgreSQL node replacement and ensure the automatic recovery of the connector, follow the guidelines below.
React to Debezium failures
The following guideline ensures no data loss in case of a Debezium connector failure and requires disabling writes to the source PoistgreSQL database.
-
After noticing a failed Debezium connector, stop all the write traffic to the database immediately.
After a node replacement, replication slots are not recreated automatically in the newly promoted database. When Debezium recovers, it will recreate the replication slot. If there were changes made to the database before the replication slot is recreated on the new primary server, then Debezium will not be able to capture them, resulting in data loss.
When this happens, you can reconfigure the connector to temporarily use
snapshot.mode=always, then restart the connector. This settings forces the connector to republish snapshot data again to the output Apache Kafka® topics. Reconfigure it back to the default once the snapshot finishes to avoid regenerating snapshot on every restart. -
Manually restart the failed tasks.
-
Confirm that the connector has created a new replication slot and that it is in active state by querying the
pg_replication_slotstable. -
Resume the write operations on the database.
Automate the replication slot re-creation and verification
The following guideline requires the setup of an automation which re-creates the replication slot on the new PostgreSQL nodes. As per Debezium docs:
There must be a process that re-creates the Debezium replication slot before allowing applications to write to the new primary. This is crucial. Without this process, your application can miss change events.
After recovering, the Debezium connector can create the replication slot on the newly promoted database if none exists, however there can be some delay in doing that. Having a separate and automated process recreating the Debezium replication slot immediately after a node replacement is fundamental to resume normal operations as soon as possible without data loss. When the connector recovers, it will capture all the changes that are made after the replication slot was created.
The example contained in the dedicated Aiven repository demonstrates a basic functionality of disabling inserts to the database unless the Debezium replication slot is active. However, it is enough to check that the replication slot to exists although it may be inactive - meaning the connector isn't actively listening on the slot yet. Once the connector starts listening again, it will capture all the change events since the replication slot was created.
The Debezium docs also suggest:
Verify that Debezium was able to read all changes in the slot before the old primary failed.
To ensure client applications receive all events captured by Debezium, implement a verification method to confirm all changes to the monitored tables are recorded.
The example contained in the dedicated Aiven repository demonstrates this implementation.
As per above guideline, setting "_aiven.restart.on.failure": true on
all Debezium connectors ensures that failed tasks are automatically
restarted in case they fail. By default tasks status is checked every 15
minutes but the interval can be customised if needed.