MirrorMaker 2 active-active setup
An active-active setup of MM2 allows data to be replicated between two clusters simultaneously. It implies a bidirectional mirroring between the two clusters. In order to do this, MM2 uses topic prefixes in the form of <cluster alias>.<topic name>
In this setup, there are two actively used Apache Kafka® clusters: Cluster K1 and cluster K2. Topic exists in both clusters.
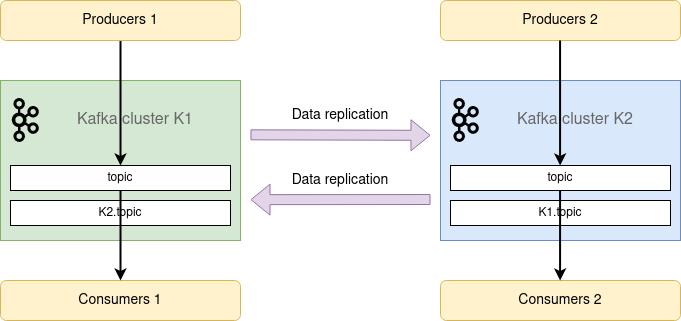
Each cluster has its producers and consumers. Producers produce to a topic, while consumers consume from the same topic using the same group.id. MirrorMaker 2 replicates data between clusters in both directions, so remote topics K1.topic and K2.topic exist in K2 and K1, respectively.
In case a disaster happens to the K1 cluster, and it becomes inaccessible for a long time for all the clients as well as MirrorMaker 2, the replication will stop, leaving some data un-replicated in both clusters.
The clients (Producers 1 and Consumers 1) switch from K1 to K2. Consumers 1 continue consuming from the remote (i.e., replicated) topic K1.topic, Producers 1 start producing into a topic.
When Consumers 1 finish consuming K1.topic, they switch to a new topic. All consumers act as one group.
When K1 is recovered, its clients can switch back. Data produced by Producers 1 into the topic in K2 will be processed by Consumers 2.
Disaster recovery / high availability
This mode has bidirectional data mirroring between two clusters. It allows clients to produce and consume from both clusters simultaneously since data can be produced and consumed from either cluster.
This setup is usually utilized for high availability, but it can also be beneficial for disaster recovery as it simplifies recovery. Since data is actively replicated between the clusters at all times, the data in both clusters is identical, making failover to either cluster easy.
Implementation details
- Consumers will need to be aware of the prefixed topics and can do this using wildcards or a priority knowledge of the topics to consume from, see how to configure here.
- Karapace schemas and topic configurations are not synced and must be created in both clusters.